جهاد العمار. مهندس تعلم آلة شريك في Cohere ، مختص في البحث والتطوير في مجال تعلم الآلة.
Alammar, Jay. The illustrated Transformer. June 27, 2018 [Updated 2020].
Vaswani, Ashish, et al. "Attention is all you need." Advances in neural information processing systems 30 (2017).

تقديم منظور
عالم التعلم العميق لم يعد كما هو بعد ظهور نموذج الترانزفورمر Transformer، وهو أحد أهم نماذج تعلم الآلة في مجال معالجة اللغة الطبيعية ورؤية الحاسب، حيث يعتقد الكثير من الخبراء أن الترانزفورمر في طريقه لاستبدال أحد أهم الشبكات العصبية المفضلة في مجال التعلم العميق، ألا وهي شبكات ال RNN.
ساهم تطور الترانزفومرز في تشكيل حراك ملحوظ في مشهد الذكاء الاصطناعي، حيث أصبح هناك سباق محموم بين عمالقة التقنية في بناء نماذج الذكاء الاصطناعي المولدة ذات المعاملات البليونية. مثلا، السنة الماضية ، أعلنت مايكروسوفت عن نموذجها الضخم Turing-NLG mode ذو ال ١٧ بليون معامل، تبعتها OpenAI معلنة عن نسخة ضخمة من نموذجها المولد GPT 3 ١٧٥ بليون معامل! أخيرا نموذج DALL·E المذهل الذي ملأ الدنيا وشغل الناس بقدرته الخلاقة على توليد صور من النصوص المدخلة. (المزيد من مقالات منظور السابقة حول النماذج المولدة باستخدام الترانزفورمر - ١، ٢، ٣).
دفعتنا أهمية هذا النموذج للتقديم في هذا المقال ترجمة لأفضل ما كتب في شرح نموذج الترانزفورمر ، وهو مقال الترانزفومر المصور من كتابة المبدع جهاد العمار والذي نتشرف بترجمة شروحاته الأصيلة والمتميزة للغة العربية.
كل الشكر والتقدير للاستاذ جهاد العمار على موافقته لترجمة هذا المقال القيم ومشاركته أصول الصور التي أبدع بشكل استثنائي في اخراجها.
نتمنى لكم قراءة ماتعة!
يفيد هذا المقال الباحثين والمهندسين وعلماء البيانات المهمتين ببناء تطبيقات معالجة اللغة الطبيعية ورؤية الحاسب.
مصطلحات
ترجمة سريعة لأهم المصطلحات المتداولة
The Transformer | ترانزفورمر - المحول |
Attention , self-attention | الانتباه- الانتباه الذاتي |
Encoder | وحدة التشفير، المشفر |
Decoder | وحدة فك التشفير، مفكك التشفير |
Vector | متجه |
Tensor | موتر |
Matrix | مصفوفة |
Embedding | تضمين |
Feed-forward | التغذية للأمام |
Gradient | انحدار |
Normalization | تبسيط وتوحيد |
Positional Encoding | الترميز الموقعي |
Loss Function | دالة الخسارة |
مقدمة
في إحدى المقالات السابقة، تم التطرق إلى مفهوم الانتباه attention - أحد المفاهيم الشائعة عند الحديث عن تدريب نماذج التعلم العميق الحديثة. ساهم مفهوم الانتباه في تحسين أداء تطبيقات الترجمة الآلية عن طريق استخدام الشبكات العصبية.
في هذا المقال، سنلقي نظرة على الترانزفورمر The Transformer - وهو نموذج يستخدم الانتباه لزيادة السرعة التي يمكن تدريب هذه النماذج بها. يتفوق الترانزفورمر على نموذج الترجمة الآلية العصبية من Google في مهام محددة حيث يتميز باستخدام المعالجة المتوازية. ومؤخرا، قامت Google Cloud بتوصية استخدام الترانزفورمر كنموذج مرجعي لاستخدام عروض Cloud TPU الخاصة بـ Google.
تم تقديم الترانزفورمر في الورقة المنشورة بعنوان "الانتباه هو كل ما تحتاجه" Attention is All You Need. تمت برمجة الترانزفمور باستخدام TensorFlow وهي متوفرة كجزء من حزمة Tensor2Tensor. وكذلك نشرت مجموعة معالجة اللغة الطبيعية بجامعة هارفارد دليلاً يشرح استخدام الورقة عن طريق مكتبة PyTorch.
في هذه المقالة، سنحاول تقديم شرح مبسط للنموذج بالإضافة إلى شرح المفاهيم المستخدمة وذلك سعياً لتسهيل فهمها للمهتمين ومن تنقصهم المعرفة المتعمقة بهذا النوع من النماذج.
تحديث 2020: نشر أ. جهاد العمار مقطع فيديو لشرح "Narrated Transformer".
نظرة عامة على النموذج
كمقدمة، لنأخذ تطبيقات الترجمة كمثال. تخيل النموذج كصندوق أسود، مدخلاته هي جملة في لغة ما، ومخرجاته ذات الجملة ولكن بلغة أخرى.
ولو تعمقنا داخل هذا الصندوق الأسود، سنجد "وحدة تشفير Encoder" و "وحدة فك تشفير Decoder" متصلة ببعضهما البعض.

تتكون وحدة التشفير من حزمة من المشفرات المكدسة فوق بعضها بشكل أفقي، يقابلها بنفس العدد والاعدادات حزمة من مفككات التشفير في وحدة فك التشفير.
(ملاحظة: في البحث المنشور، استخدم الباحثون ست من المشفرات في وحدة التشفير، لكن يمكنك تجربة ارقام اخرى عند بناء النموذج).

جميع المشفرات متطابقة مع بعضها البعض في الهيكلة (وليس الوزن المسند لها). كل مشفر يمكن تقسيمه إلى طبقتين:

الطبقة الأولى هي طبقة "الإنتباه الذاتي self- attention"، وهي طبقة تساعد المشفر للنظر في كلمات محددة في الجملة المدخلة أثناء عملية التشفير. (سيتم التطرق لاحقا لمفهوم الإنتباه الذاتي في هذه التدوينة).
مخرجات هذه الطبقة تصبح مدخلات لدى الطبقة الثانية وهي "feed-forward neural network شبكة التغذية للأمام".
أما في حال مففكات التشفير، فبالإضافة إلى هاتين الطبقتين، هناك طبقة "انتباه" ثالثة تتوسطهما والتي تساعد هذه المفككات على التركيز على الأجزاء المهمة من الجملة المدخلة (بطريقة مماثلة لما يفعله الانتباه في توليفة نماذج seq2seq) .

الموترات (Tensors) ودورها الجديد في الترانزفورمز
بعد أن أصبح لدينا تصور واضح عن مكونات النموذج بشكل مبسط، سوف نركز الآن على كيفية استخدام المتجهات/الموترات vectors/tensors المتعددة، والتي تنتقل بين هذه المكونات والطبقات برشاقة لتحويل مدخلات النموذج المدرب إلى مخرجات ذات معنى.
وكحال أي تطبيق لمعالجة اللغة الطبيعية، نستهل بأول خطوة، ألا وهي تحويل كل كلمة مدخلة إلى متجه باستخدام خوارزميات التضمين (embeddings).

يتم تضمين كل كلمة بمتجه حجمه ٥١٢ (ممثلة كمربعات في الصورة السابقة). تبدأ عملية التضمين في المشفر الواقع في قاع حزمة المشفرات والذي سيمرر لاحقا مخرجات هذا التضمين لباقي المشفرات المتكدسة فوقه.
يتم تحديد طول قائمة المتجهات التي يمكن تمريرها في خلال المشفرات (والذي عادة يوافق طول أطول جملة في بيانات التدريب) عبر معاملات النموذج hyperparameters.
بعد الانتهاء من تضمين الكلمات وتحويلها إلى متجهات، تبدأ المتجهات بالانتقال بانسيابية بين طبقات المشفر.

هنا تظهر أهم معالم نموذج الترانزفورمر، ألا وهي معاملة الكلمات المدخلة بشكل مستقل و متوازي.
عند دخول الكلمات للمشفر، يتحدد لكل كلمة مسار خاص (حسب موقعها في الجملة). وعلى الرغم من استقلالية هذه المسارات، تشكل طبقة الانتباه الذاتي داخل المشفر ارتباطات بين هذه المسارات سنوضح سببها لاحقا. تذوب هذه الارتباطات لاحقا عند الانتقال لطبقة التغذية الأمامية حتى يتم التعامل مع هذه المسارات بشكل متوازي.
في الخطوة التالية، سنقوم بتحويل المثال من كلمات إلى جمل قصيرة لنفهم ماذا يحدث في كل طبقة بشكل أوضح.
يبدأ التشفير الآن!
كما ذكرنا سابقا، يستقبل المشفر قائمة من المتجهات كمدخلات. تتم معالجة هذه القائمة عبر تمريرها لطبقة الانتباه الذاتي ثم لطبقة التغذية الأمامية، وبعد الانتهاء من المعالجة، يتم تمرير المخرجات للمشفر الواقع في الأعلى لتكرار نفس العملية.

وكما أسلفنا، فإن كل كلمة في الجملة (أو متجه) تشق مسارها الخاص في طبقة الانتباه الذاتي، ومن ثم تمر بشبكة عصبية خاصة به في طبقة التغذية الأمامية. مع التنويه أن عدد الشبكات العصبية في هذه الطبقة يساوي عدد المتجهات المدخلة لضمان معالجة المتجهات بشكل متوازي.
الانتباه الذاتي مُجرداً
لنأخذ هذه الجملة كمثال للترجمة من اللغة الانجليزية للعربية
”The animal didn't cross the street because it was too tired”
لنسأل أنفسنا هذا السؤال: على ماذا يعود الضمير المنفصل المشار باللون الأحمر في الجملة السابقة؟
هل يعود على الكلمة المشار إليها باللون الأزرق (الحيوان) ؟
أم المشار إليها باللون الأخضر (الشارع) ؟
كبشر، نحن نستطيع تكوين هذا الارتباط بسهولة، لأن الصفة الموضحة باللون الأصفر (متعب) لا يمكن ربطها بشيء جامد (الشارع) و إنما (الحيوان). لكن كيف للخوارزميات فهم هذا الارتباط؟
يظهر هنا الدور الجوهري لطبقة "الانتباه الذاتي" ، والتي تقوم بربط الضمير المنفصل في الجملة أعلاه بما يعود عليه، وهو الحيوان في هذا المثال.
فعندما تتم معالجة كل كلمة في كل جملة، يقوم الانتباه الذاتي بتنبيه النموذج في حال وجود ارتباط محتمل بين الكلمة المعالجة وكلمات أخرى موجودة في الجملة المدخلة حتى يتم تشفير هذه الكلمة بشكل صحيح.
يقدم الانتباه الذاتي مفهوما مقاربا ( مع اختلاف طفيف) للشبكات العصبية المتكررة RNN والتي تحافظ على ميزة "الحالة المخفية" hidden state حتى تشمل تمثيل المتجه الذي سبق معالجته مع المتجه الجاري معالجته. وبالتالي الانتباه الذاتي يساعد الترانزفورمر ليصل إلى فهم أفضل للارتباط والعلاقات بين الكلمة التي تتم معالجتها وبقية الكلمات في الجملة المدخلة.

يوضح المثال المصور ما يحدث في طبقة الانتباه الذاتي في المشفر رقم خمسة (أعلى/آخر مشفر في حزمة المشفرات)، حيث يتم التركيز ضمن المعالجة على "The Animal" وربط جزء من تمثيلها بالضمير "it".
هنا مثال تطبيقي حيث يمكنك تحميل نموذج الترانزفورمر وفحصه عبر التمثيل المصور المقدم.
الإنتباه الذاتي مُفصلاً!
نستعرض هنا كيف يتم حساب الانتباه الذاتي باستخدام المتجهات وكيف يتم تطبيق نفس الحسابات باستخدام المصفوفات.
أول خطوة في حساب الانتباه الذاتي هي إنشاء ٣ متجهات لكل كلمة مدخلة: متجه الطلب Query vector ، متجه المفتاح Key vector ومتجه القيمة Value vector.
كل متجه يتم حسابه عبر ضرب تضمين الكلمة المدخلة في ٣ مصفوفات matrices تم تدريبها مسبقاً.
(في هذا المثال، المتجهات الثلاثة أصغر من متجهات تضمين الكلمات المدخلة. مثلاً، أبعاد المتجهات هنا ٦٤ بينما أبعاد تضمين الكلمات المدخلة هي ٥١٢. يجب التنويه حجم الأبعاد هنا ليس بقاعدة، وإنما كان هذا اختيار الباحثين لتحسين أداء العمليات الحسابية).

كما هو موضح في الصورة، ضرب تضمين الكلمة المدخلة x1 في المصفوفة WQ ينتج متجه الطلب query، وهكذا دواليك لباقي المتجهات (المفتاح والقيمة) والتي ستسخدم لاحقاً لتمثيل كل كلمة في الجملة المدخلة.
ماهي متجهات الطلب، المفتاح والقيمة؟
لنستخدمها في البداية كمصطلحات تجريديه حتى نفهم ماذا يعني "الانتباه". بمجرد أن تكمل قراءة كيف يتم حساب الانتباه في هذه المقالة، ستسوعب بشكل أفضل الدور الفعال الذي تلعبه هذه المتجهات الثلاثة.
الخطوة التالية في حساب الانتباه الذاتي تتمحور حول حساب درجة معينة score.
هنا مثال: لنفترض أننا نرغب في حساب الانتباه الذاتي لأول كلمة في المثال المصور أدناه (Thinking).
نحتاج في هذه المرحلة أن نحسب درجة لكل كلمة في الجملة المدخلة على حسب ارتباطها بكلمة (Thinking) وذلك لتحديد مناطق التركيز الأخرى في الجملة المدخلة عند تشفير تلك الكلمة.
هذه الدرجة هي حاصل الضرب القياسي dot product لمتجه الطلب للكلمة المراد معالجتها ومتجه المفتاح لكلمة رقم س في الجملة المدخلة.
مثلا، إذا كنا نرغب في حساب الانتباه الذاتي للكلمة الأولى في الجملة، (Thinking) في هذه الحالة، درجة الكلمة الأولى ستكون حاصل الضرب القياسي لمتجه الطلب لكلمة (Thinking - k1- ومتجه المفتاح للكلمة الإولى هذه الجملة k1). والدرجة الثانية ستكون حاصل الضرب القياسي لمتجه الطلب لكلمة(Thinking - k1- ومتجه المفتاح للكلمة الثانية في هذه الجملة k2).

الخطوة الثالثة والرابعة هي قسمة الدرجات على ٨ (تم اختيار هذا الرقم تحديدا، وهو الجذر التربيعي لأبعاد متجهات المفتاح -٦٤، للحصول على gradient انحدار أو ميل مستقر) ومن ثم تبسيط النتائج normalization لجعلها موجبة ومجموعها يساوي ١ وذلك عبر تمريرها لعملية softmax.

عملية softmax ستحدد مدى ارتباط كل كلمة في الجملة المدخلة مع الكلمة المراد معالجتها، مثلا مدى ارتباط كلمة (machines) مع كلمة (Thinking).
من المنطقي أن تكون أعلى قيمة softmax لكلمة المعالَجة هي ذات الكلمة (كما هو الحال في كلمة ارتباط كلمة Thinking بنفسها)، لكن من المهم كذلك حساب الارتباط مع باقي الكلمات لبناء السياق المطلوب.
الخطوة الخامسة، وهي التركيز على الكلمات ذات العلاقة للكلمة المراد معالجتها، ويتم ذلك عبر ضرب كل متجه بدرجة softmax الخاصة به. وبالتالي ستتضخم قيم الكلمات ذات العلاقة (عبر قيمة ال softmax العالية) ومن ثم التركيز عليها، وستتضائل قيمة الكلمات الغير مرتبطة ذات ال softmax المنخفض ومن ثم تجاهلها.
الخطوة السادسة هي الجمع الموزون المتجهات، أي حاصل جمع جميع المتجهات بعد ضربها بال softmax الخاص بها من الخطوة الخامسة. يمثل المخرج من هذه العملية النتيجة النهائية لحساب الانتباه الذاتي للكلمة المراد معالجتها في تلك المرحلة.

وهكذا يتم حساب الانتباه الذاتي لكل كلمة في كل طبقة حيث يكون الناتج النهائي عبارة عن متجه يمرر بعد ذلك الى شبكة التغذية الأمامية.
عمليا، لتسريع العمليات الحسابية، يتم استخدام المصفوفات لإتمام حساب الانتباه الذاتي لجملة الكلمات. الجزء التالي يشرح ذلك بالتفصيل.
حساب الانتباه الذاتي باستخدام المصفوفات
في الخطوة الأولى يتم حساب مصفوفات الطلب، المفتاح والقيمة. و ذلك يتم ببساطة عبر ترتيب تضمينات الكلمات في مصفوفة X ثم ضرب في مصفوفات الوزن التي تم تدريبها مسبقا WQ،WK،
.WV

كل صف في مصفوفة X يمثل كلمة في الجملة المدخلة (الصف ذو ٤ مربعات يكافئ ٥١٢، والصف ذو ٣ مربعات يكافئ ٦٤).
.
وبهذه الطريقة يمكننا دمج الخطوات السابق ذكرها (٢ ألى ٦) في عملية حسابها واحده لحساب الانتباه الذاتي في كل طبقة.

وبالتالي نحصل على مصفوفة حساب الانتباه الذاتي (الموضحة في الصورة أعلاه)
الهايدرا المتعددة الرؤؤس
في البحث المنشور تم إعادة تصميم طبقة الانتباه الذاتي عن طريق إضافة آلية "تعدد الرؤوس". تحسن هذه الآلية آداء طبقة الانتباه عبر طريقتين:
١. تطوير قدرة النموذج على التركيز على أكثر من كلمة في نفس الوقت.
٢. تعدد مساحات التمثيل في طبقة الانتباه حيث يصبح هناك مصفوفات متعددة للطلب، المفتاح والقيمة. يستخدم الترانزفورمر ٨ رؤوس للانتباه وبالتالي ٨ مجموعات من المشفرات ومفككات التشفير. وفي كل مجموعة يتم اسناد قيم أولية بشكل عشوائي ثم استخدامها لتمثيل قيم التضمين للكلمات المدخلة في مساحة تمثيل خاصة.

الصورة السابقة تشرح ذلك، أصبح لدينا مصفوفة مستقلة لكل من الطلب والمفتاح والقيمة لكل رأس انتباه والتي هي حاصل ضرب مصفوفة الكلمات المدخلة في مصفوفات WQ/WK/WV.
وبالتالي ، تكرار حساب مصفوفة الانتباه بالطريقة التي تم شرحها سابقا لكل من الثمان رؤوس، يؤدي إلى الحصول علـي ٨ مصفوفات Z.

لكن طبقة التغذية الأمامية تستقبل فقط مصفوفة واحدة مخرجة، كل صف فيها يمثل حساب الانتباه لكل كلمة مدخلة- لذلك سيتم اعادة تمثيل المصفوفات المخرجة من الرؤوس المتعددة بحيث يتم تكديسها في مصفوفة واحدة فقط عبر عملية ضم المصفوفات Concatenation ثم ضربها بمصفوفة الوزن WO حتى نعكس التأثير الحقيقي لكل كلمة.

الصورة التالية تلخص كل ما سبق :

بعد ما تم توضيح مفهوم الانتباه المتعدد الرؤوس، لنرجع إلى مثالنا السابق حتى نفهم كيف تعمل هذه الرؤوس عندما نعالج الضمير المنفصل it في مثالنا السابق.

هنا تظهر أهمية تعدد الرؤوس: في الوقت الذي يتم معالجة فيه كلمة it، سيكون هناك رأس انتباه (اللون البرتقالي) يركز علـى كلمة the animal، ورأس آخر (اللون الاخضر) يركز على كلمة tired . وبالتالي فـإن تمثيل النموذج لكلمة it سيكون مرتبط بتمثيل الكلمتين the animal و tired.
الصورة التالية تمثل الانتباه بعد اضافة جميع الرؤوس الثمانية.

طريقة تمثيل ترتيب سلسلة الكلمات باستخدام الترميز الموقعي
الحلقة المفقودة في في النموذج الحالي هو عدم وجود طريقة للأخذ في عين الاعتبار ترتيب الكلمات في الجملة المدخلة.
لحل هذه المشكلة، يضيف الترانزفومر متجه خاص لكل تضمين كلمة. هذه المتجهات تتبع نمط معين يتعلمه النموذج والذي يساعد في تحديد موقع كل كلمة (أو المسافات بين الكلمات المختلفة في الجملة).
ربط هذه المتجهات بتضمين الكلمات المدخلة سيضيف ترتيب واضح للتضمينات المدخلة عند عكسها في متجهات الطلب والمفتاح والقيمة وخلال مرحلة حساب الانتباه.

تسمى هذه المتجهات ب متجهات الترميز الموقعي والتي تعطي ايحاء بموقع كل كلمة في الجملة المدخلة.
كما أسلفنا، قيم هذه المتجهات تتبع نمط معين يتعلمه النموذج حول ترتيب الكلمات.
هنا مثال لقيم متجهات الترميز الموقعي على افتراض أن تضمين الكلمات المدخلة ذات ٤ أبعاد.

هذا النمط..كيف يبدو؟
الصورة التالية توضح مثال لمتجهات الترميز الموقعي ل ٢٠ تضمين كلمة (ممثلة بالصفوف) في جملة مدخلة بحجم ٥١٢ (عدد الاعمدة). كل صف يمثل متجه للترميز الموقعي . مثلا الصف الأول يمثل متجه الترميز الموقعي الذي تم اضافته لتضمين الكلمة الأولى في الجملة المدخلة وهكذا. يحتوي كل صف على ٥١٢ قيمة بين ١ و -١ . تم استخدام الألوان في هذه الصورة لتمثيل هذه القيم حتى يظهر شكل النمط الذي ننوي دراسته.
الملاحظة الأولى أن هناك انقسام في المنتصف والسبب أن القيم في النصف الأيسر من المتجه تم حسابها باستخدام دالة جا sin ، بينما النصف الايمن تم حسابه باستخدام دالة جتا cos. يتم بعدها ضم القيمتين لتكوين متجه الترميز الموقعي.

يمكنكم الاطلاع علي العمليات الحسابية الخاصة بمتجهات الترميز المكاني في قسم 3.5 في البحث المنشور. كما يمكن الحصول على الكود لهذه العمليات في الرابط التالي.
هذه ليست الطريقة الوحيدة لحساب المتجهات الموقعية ولكن تتميز هذه الطريقة بامكانيه تطبيقها على أي سلسلة من الكلمات بغض النظر عن طولها (خصوصا في حال معالجة جمل طويلة لم يسبق للنموذج التدريب معالجتها في بيانات التدريب).
تحديث (يوليو 2020). الترميز المكاني المشروح سابقا مأخوذ من طريقة Tranformer2Transformer، بينما الطريقة المشروحة في البحث تختلف بشكل طفيف حيث أنها لا تنفذ عملية ضم المتجهات الموقعية بشكل متتالي بطريقة مباشرة ولكن تُداخل فيما بينهما كماهو موضح في الصورة التالية (هنا رابط الكود الخاص بهذه العملية)

الفروقات
ينبغي علينا شرح جزئية مهمة في تركيب المشفر قبل الإكمال، وهي أن كل طبقة في الانتباه الذاتي لكل مشفر تحتوي على مكون لحساب الفروقات residuals. ويلي هذا المكون طبقة التبسيط
.normalization

الصورة في الأسفل تصور هذه المتجهات بالإضافة إلى عمليات التبسيط layer-norm التي تتم في كجزء من عمليات الحساب في الانتباه الذاتي.

وكذلك الحال في مفكات التشفير، إذ يحتوي كل مفكك تشفير على مكونات تقوم بعمل عمليات مشابهة للتي تتم في المشفرات. الصورة التالية توضح الطبقات المختلفة في كل من المشفرات ومفكرات التشفير في الترانزفمور.

جانب مفككات التشفير
بعد أن تم شرح المفاهيم المختلفة للعمليات التي تتم في المشفرات، يمكن القول أن مفككات التشفير تقوم بعمليات مماثلة لنظيرتها في المشفرات.
تبدأ عملية فك التشفير بمعالجة سلاسل المدخلات. تتم المعالجة في أول مفكك شفرات والذي بدوره يقوم بتمرير مخرجاته إلى المفكك الذي يليه بعد تحويل المخرج إلى مجموعة من متجهات الانتباه K و V. هذه المتجهات يتم استخدامها بواسطة كل مفكك شفرات وبالتحديد في طبقة encoder-decoder attention والتي بدورها تسمح لمفكك الشفرات أن يركز على مواقع الكلمات في سلسلة المدخلات.
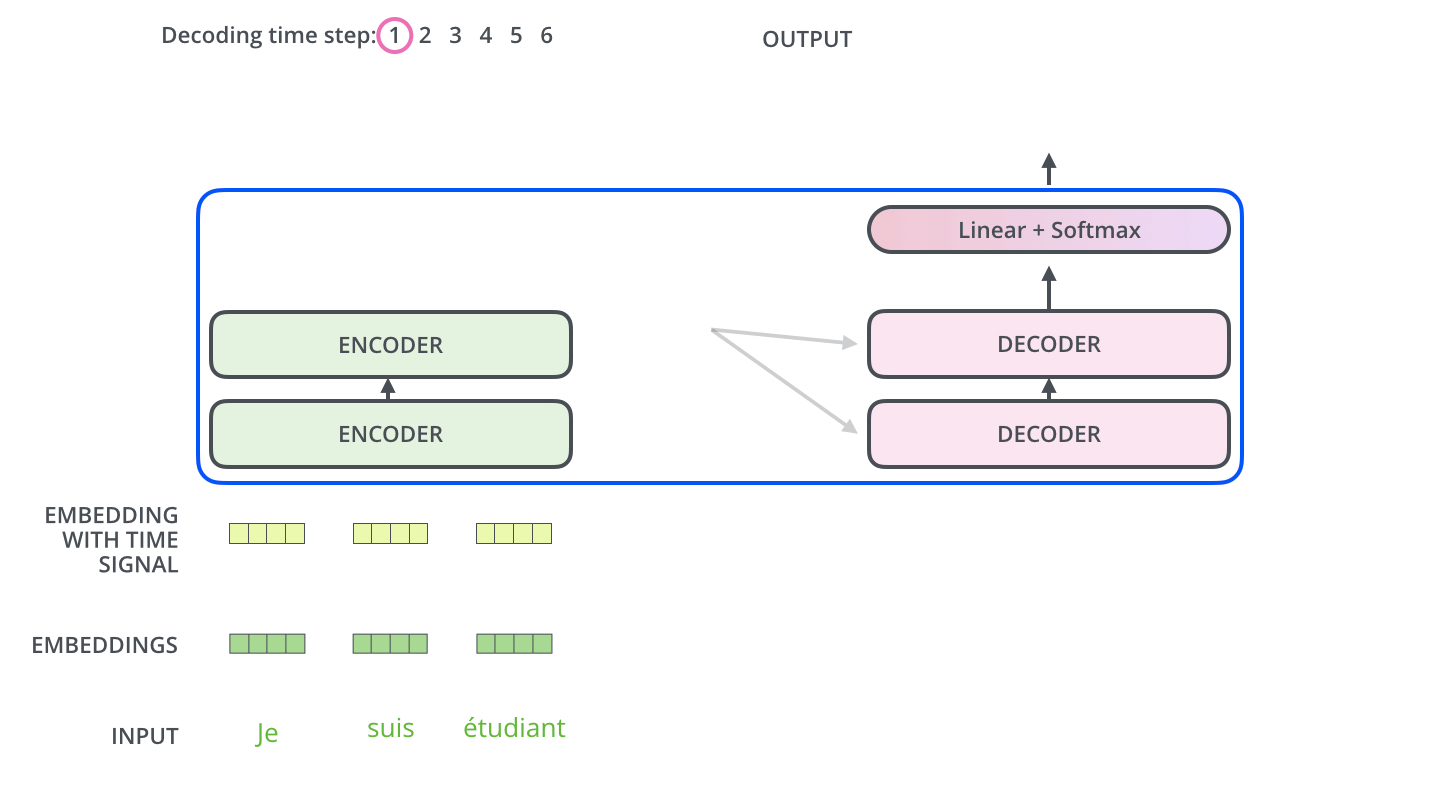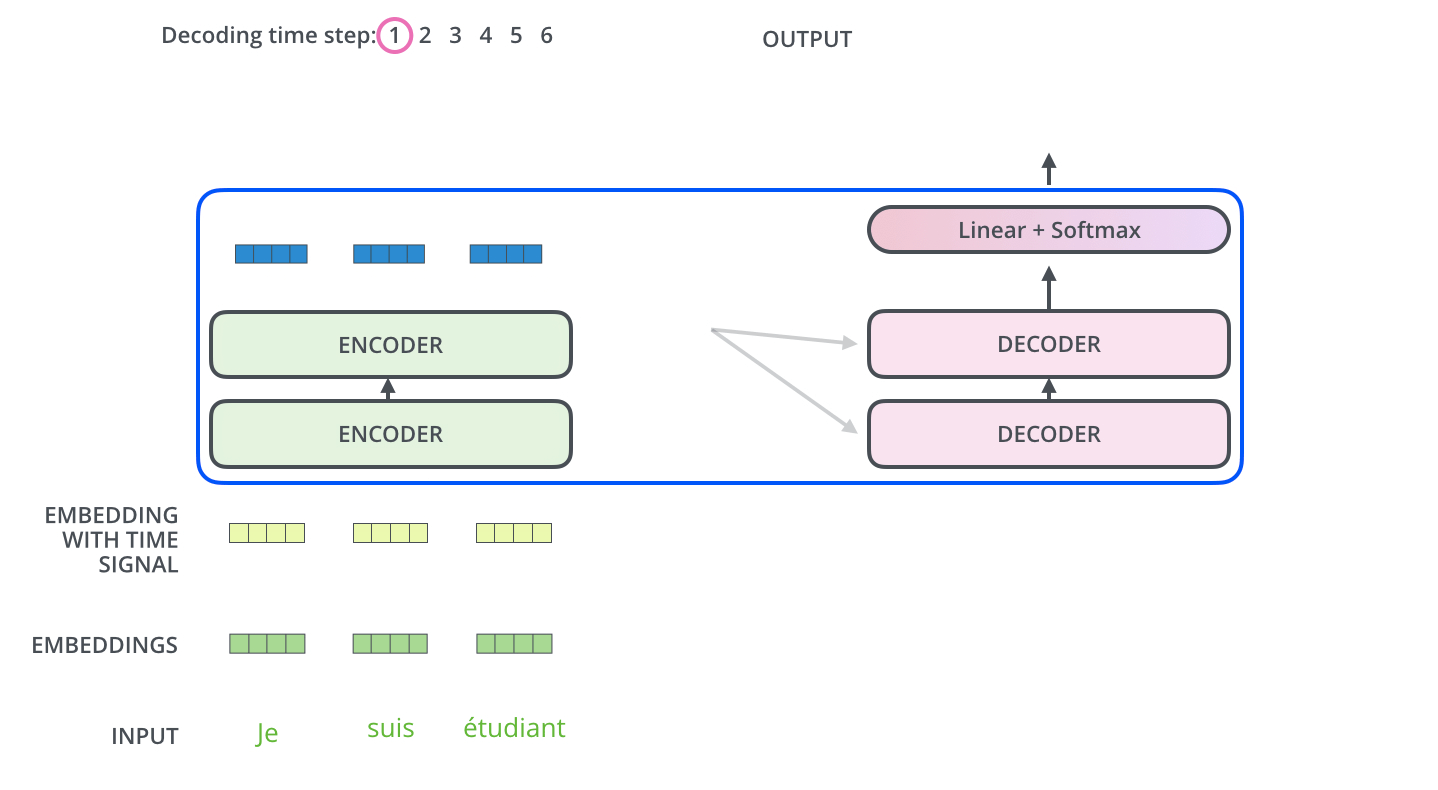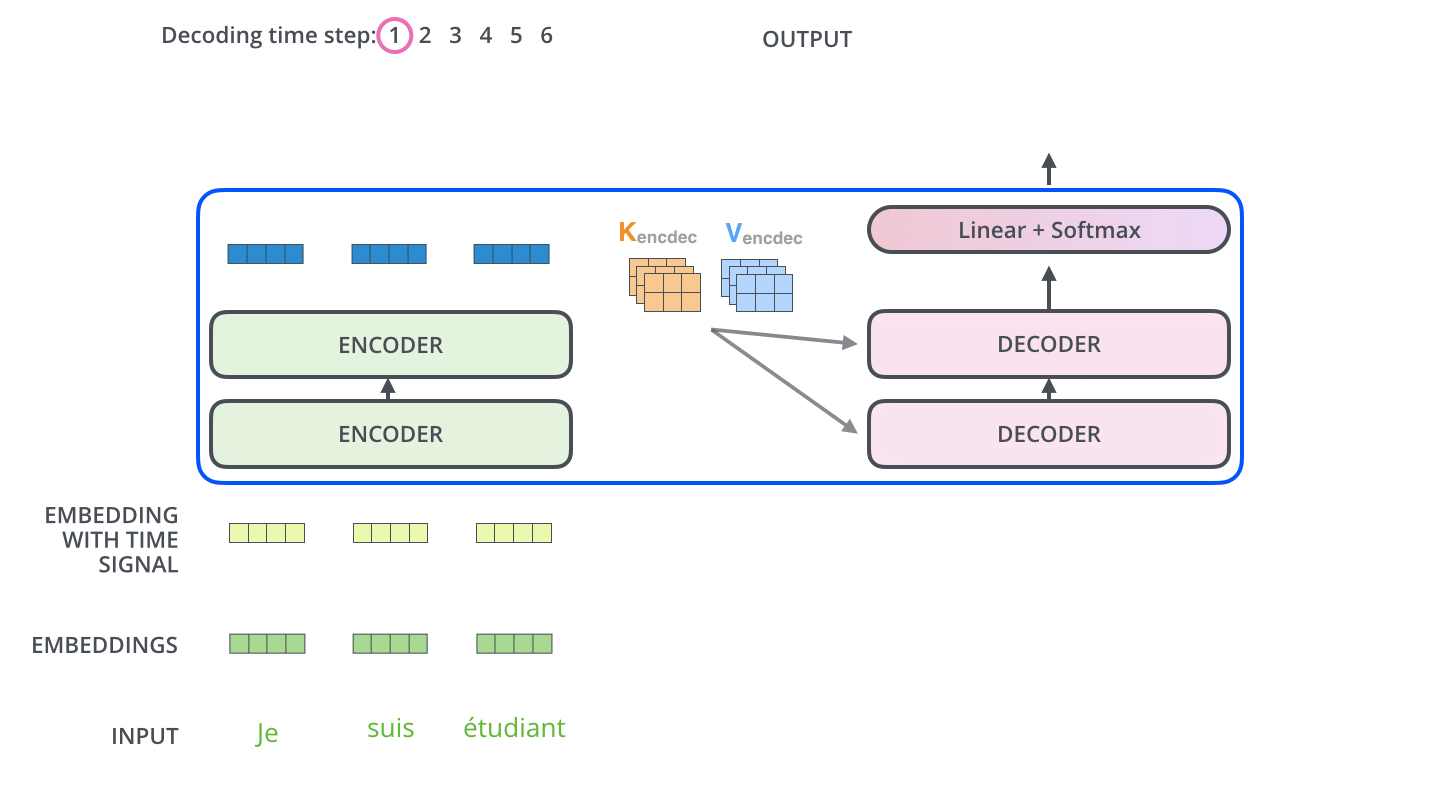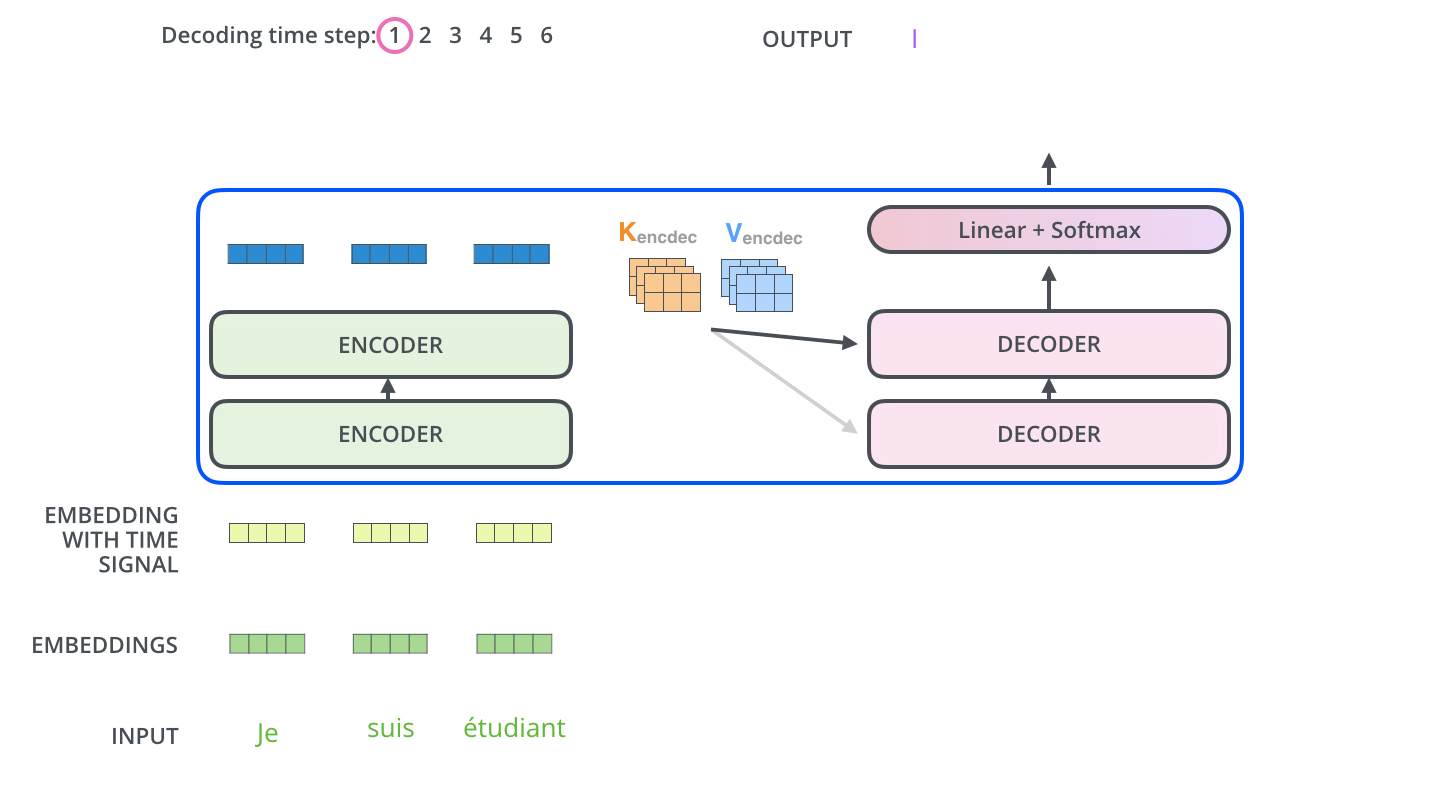
بعد أن انتهاء عملية التشفير يبدأ مفكك الشفرات عمله، وكل خطوة في العمليات الخاصة بمفكك الشفرات تنتج عنصر من عناصر سلسلة المخرجات. في المثال الموضح بالصورة سلسلة المخرجات عبارة عن الترجمة للجملة الفرنسية المدخلة للغة الإنجليزية.
يتم تكرار هذه العملية إلى أن يتم الوصول إلى رمز خاص إيذاناً باكتمال عملية التشفير. وكما هو الحال في المشفر يتم إدخال المخرج في كل خطوة من خطوات فك التشفير إلى مفكك الشفرات الذي يلي المفكك الحالي. كما تقوم مجموعة مفككات التشفير بتجميع مخرجاتها وتضمين مواقع الكلمات بنفس الطريقة المتبعة في المشفر بحيث يتم المحافظة على مواقع الكلمات في سلسلة المخرجات.
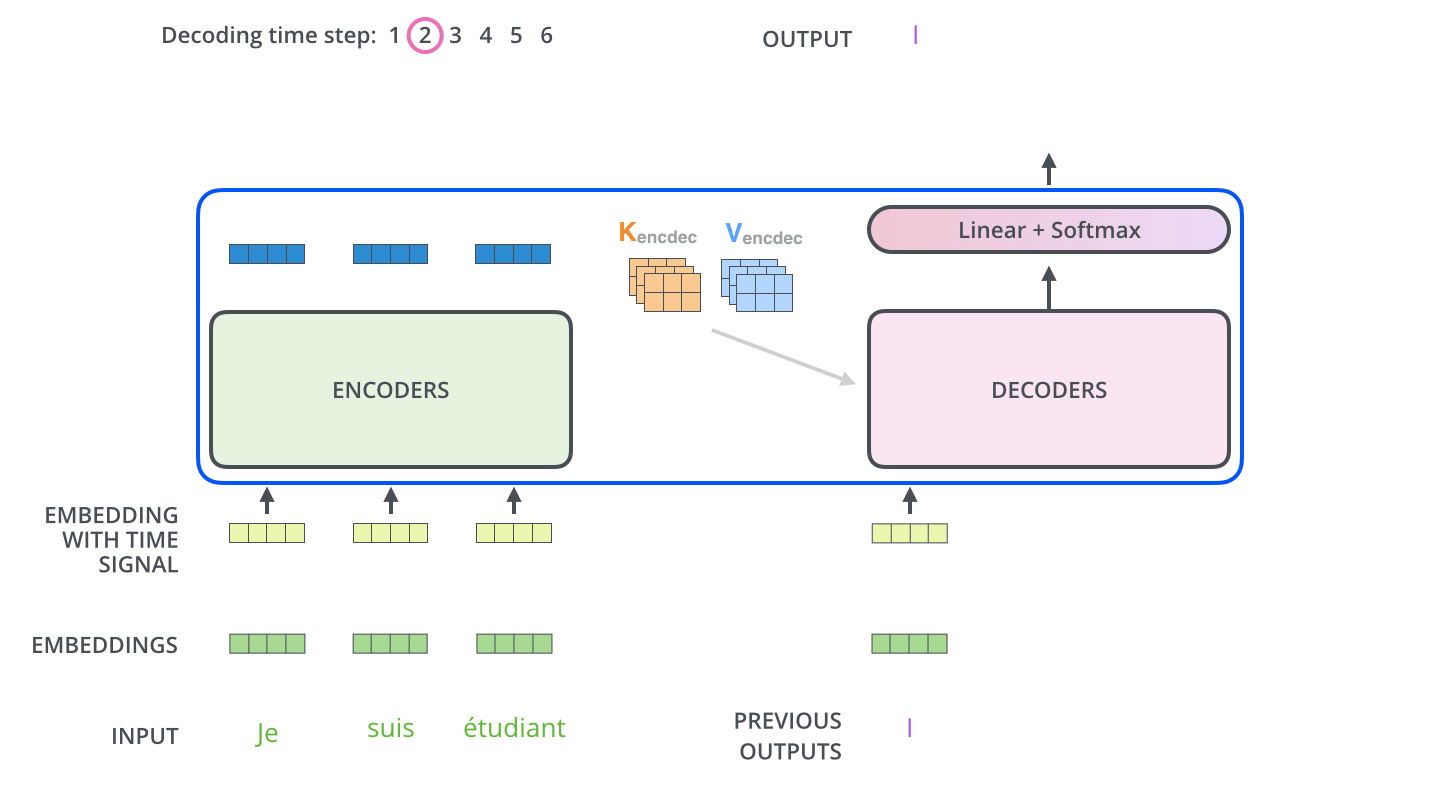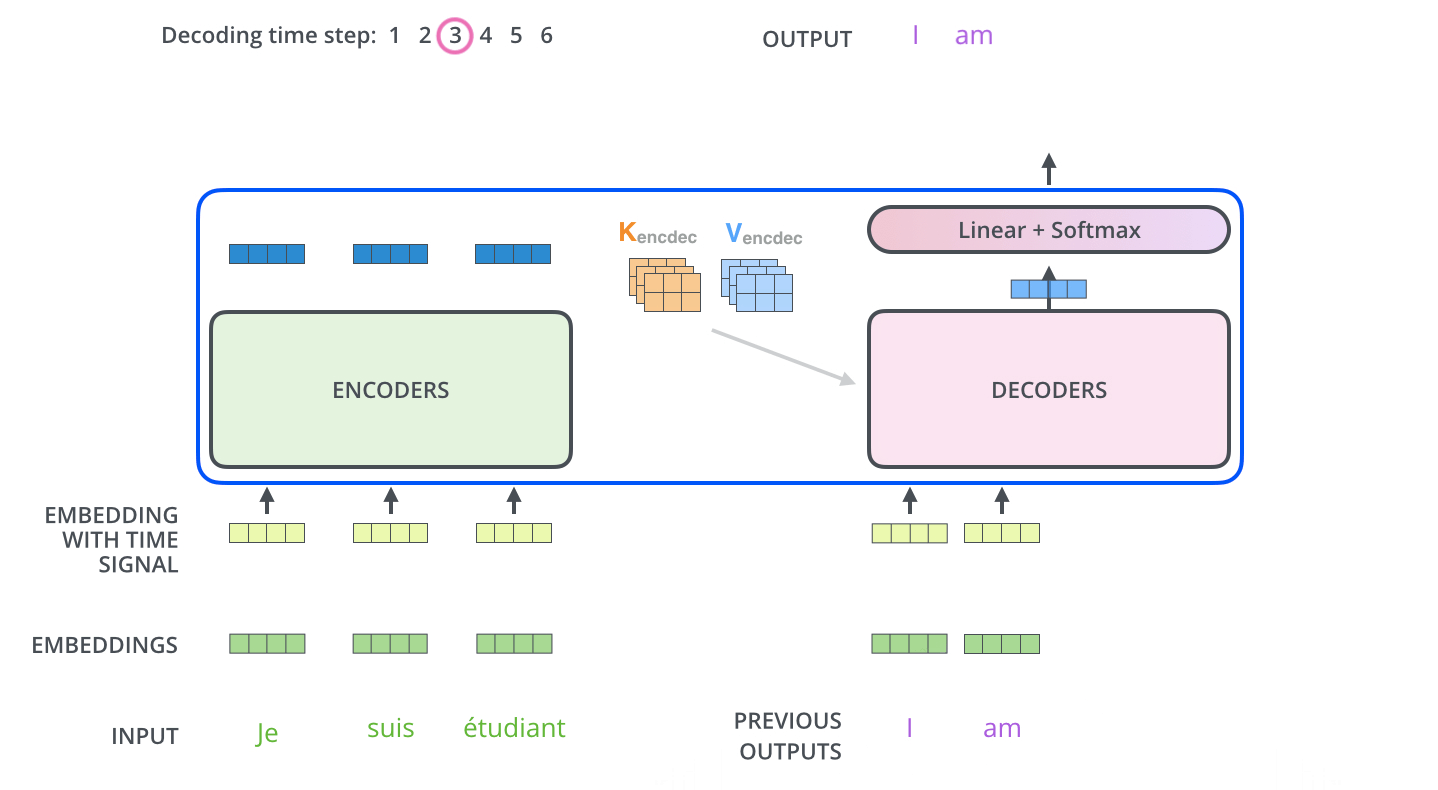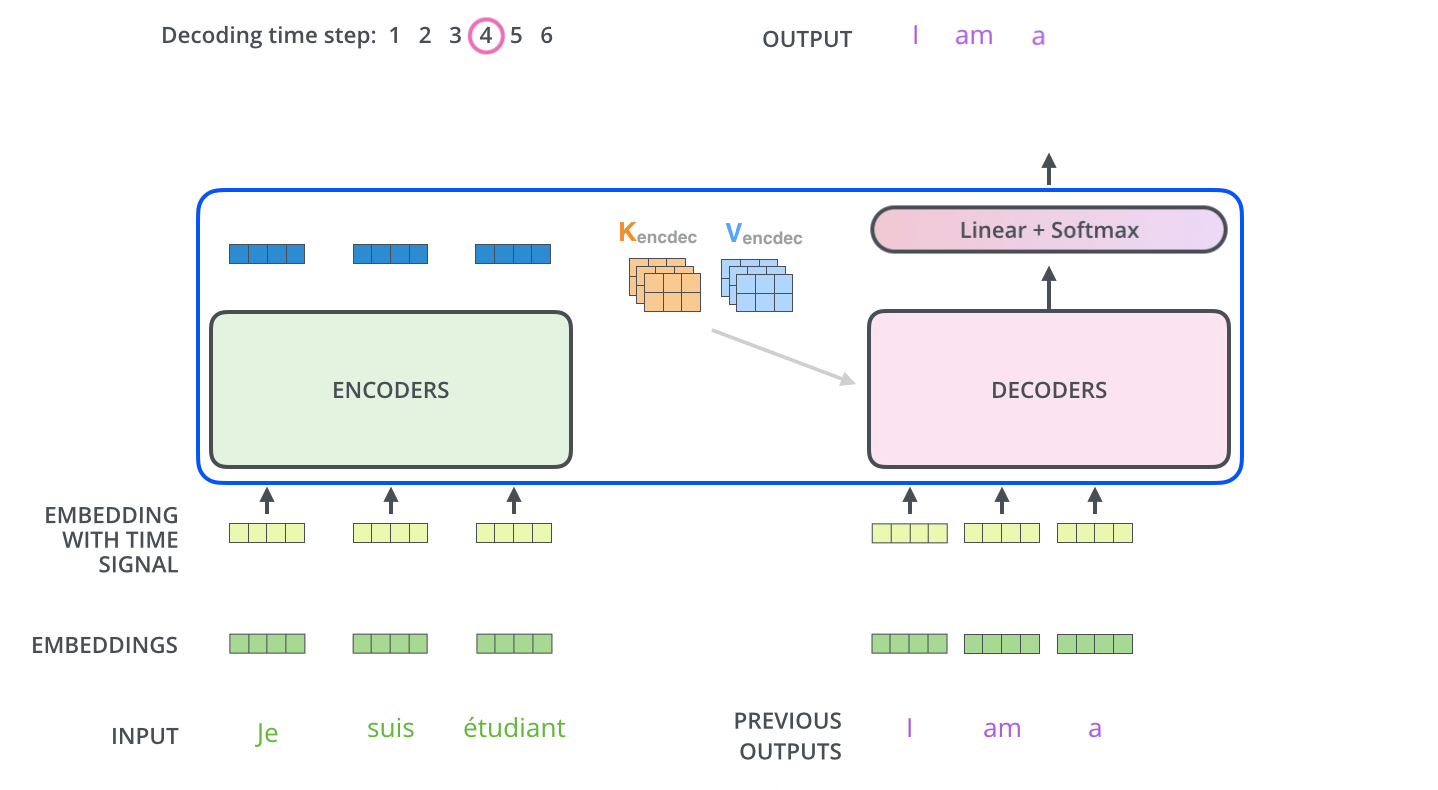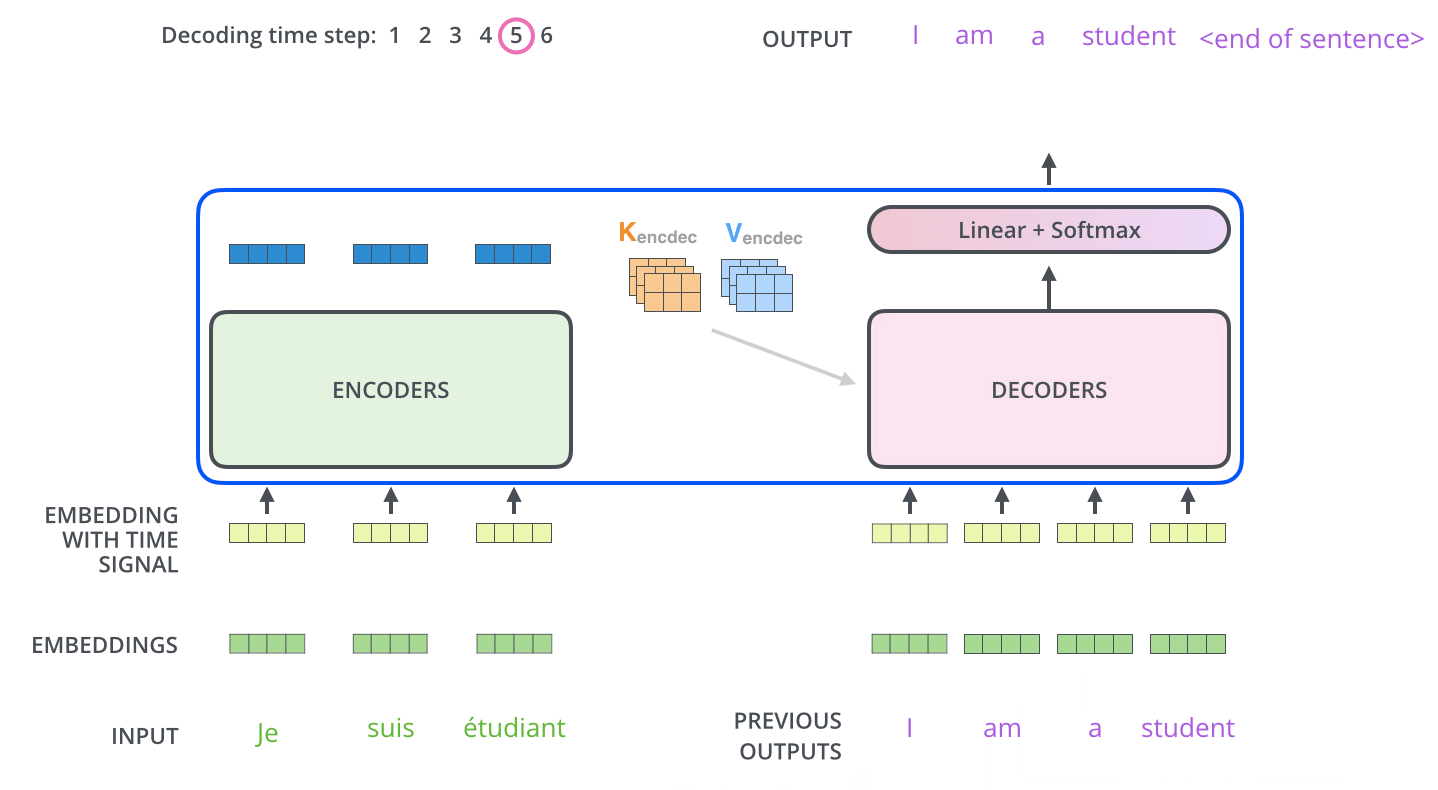
ورغم ذلك يوجد فارق بسيط ما بين طريقة عمل طبقات الانتباه الذاتي في مفككات التشفير إذا قورنت بالطبقات المماثلة في المشفرات. هذا الفارق على النحو التالي:
في مفككات التشفير، يُسمح فقط لطبقة الانتباه الذاتي بالتركيز على المواضع السابقة في سلسلة المخرجات. يتم ذلك عن طريق إخفاء المواقع المستقبلية قبل خطوة softmax في حساب الانتباه الذاتي.
تعمل طبقة "Encoder-Decoder Attention" بطريقة مماثلة لطريقة عمل الانتباه الذاتي متعدد الرؤوس، إلا أنها تنشئ مصفوفة Q الخاصة بها من الطبقة الموجودة أسفلها، كما تأخذ مصفوفي K و V من مخرجات المشفرات المكدسة.
الطبقتين الأخيرتين: الخطية linear والسوفت ماكس softmax
تقوم مفككات التشفير بتكديس المخرج النهائي على شكل متجه مكون من مجموعة من القيم العشرية floats، والسؤال هنا هو كيف يمكننا تحويل هذه القيم إلى كلمة؟ هذه بالتحديد هي مهمة الطبقة الخطية الأخيرة linear والتي تليها طبقة السوفت ماكس softmax.
ببساطة، الطبقة الخطية هي عبارة عن شبكة عصبية متصلة تقوم بتحويل متجه القيم العشرية (المخرج من حزمة مفككات التشفير المكدسة) إلى متجه أكبر بكثير يسمى متجه اللوغاريتمات logits vectors.
لنفترض أن نموذجنا يعرف معجما مكونا من 10,000 كلمة إنجليزية فريدة والتي تم تدريب النموذج عليها عن طريق بيانات التدريب. هذا من شأنه أن يجعل عرض متجه اللوغاريتمات 10,000 خلية - بحيث تتصل كل خلية مع القيمة الخاصة بأحدى الكلمات الفريدة في المعجم. وبهذه الطريقة، نستطيع أن نفسر نتائج النموذج بعد المرور بالطبقة الخطية.
تقوم طبقة السوفت ماكس softmax بعد ذلك بتحويل هذه القيم إلى احتمالات probabilities (قيم الاحتمالات جميعها موجبة بحيث يكون مجموعها يساوي ١). يتم اختيار الخلية ذات أعلى قيم احتمال، ويتم اعتبار الكلمة المرتبطة بهذه القيمة المخرج النهائي لهذه الخطوة.

الصورة بالأعلى توضح العمليات التي تتم في هذه الخطوة، إذ يتم البدء من الطبقة الخطية ومن ثم السوفت ماكس ليتم في الأخير انتاج المخرج النهائي لمجموعة مفككات التشفير المكدسة وهو متجه المخرجات، والذي بدوره يتم تحويله إلى كلمة.
ملخص خطوات التدريب
الآن، بعد أن تم توضيح عمليات forward-pass التي يقوم بها الترانزفومر المدرب، سيكون من المفيد أن نسلط الضوء على عملية الانتباه أثناء تدريب النموذج.
أثناء التدريب، يمر النموذج غير المدرب بنفس طريقة عمل forward-pass بالضبط. ولكن نظرًا لأننا نقوم بتدريبها على مجموعة بيانات تدريب موسومة labeled، يمكننا مقارنة مخرجاتها بالمخرجات الصحيحة.
لتوضيح هذه العملية، لنفترض أن معجم المفردات المخرجة من النموذج تحتوي فقط على ست كلمات ("a" و "am" و "i" و "thanks" و "student" و "<eos>" (اختصار لـ "نهاية الجملة" end of sentence)) .

يتم إنشاء معجم المفردات المخرجة من النموذج في مرحلة المعالجة المسبقة قبل أن نبدأ التدريب.
بمجرد تحديد معجم مفردات المخرجات الممكنة، يمكننا استخدام متجه عرضه = عدد الكلمات للإشارة إلى كل كلمة في مفردات المعجم. يُعرف هذا أيضًا باسم one-hot encoding. على سبيل المثال ، يمكننا الإشارة إلى كلمة "am" باستخدام المتجه التالي:

بعد هذا الملخص، دعونا نوضح وظيفة دالة الخسارة loss function للنموذج، وهي عبارة عن القيمة التي نسعى لتحسينها خلال مرحلة التدريب وبالتالي سوف يتحسن النموذج ليصبح نموذج مدرب ودقيق بشكل كبير.
دالة الخسارة loss function
لنفترض أننا نقوم بتدريب النموذج، ولنفترض أنها الخطوة الأولى في مرحلة التدريب، حيث سيتم تدريب النموذج على مثال بسيط - ترجمة "merci" إلى "thanks".
ما يعنيه هذا هو أننا نريد أن يكون الناتج عبارة عن توزيع احتمالي probability distribution يشير إلى كلمة "thanks". ولكن نظرًا لأن هذا النموذج لم يتم تدريبه بعد، فمن غير المرجح أن يحدث هذا الأمر.

ونظرًا لأن جميع معاملات النموذج (الأوزان weights) تتم تهيئتها بشكل عشوائي ، فإن النموذج (غير المدرب) ينتج توزيعًا احتماليًا بقيم عشوائية لكل خلية / كلمة. وبالتالي، يمكننا مقارنته بالمخرجات الفعلية، ومن ثم يتم تعديل جميع أوزان النموذج باستخدام الانتشار العكسي backpropagation لجعل المخرجات أقرب إلى الناتج المطلوب.
ولكن كيف نقارن ما بين توزيعين احتماليين؟ ببساطة نطرح أحدهما من الآخر. لمزيد من التفاصيل، انظر إلى الانتروبيا التقاطعية و Kullback – Leibler divergence.
لنستخدم جملة تحتوي على أكثر من كلمة واحدة. مثلا: الجملة المدخلة هي "je suis étudiant" والمخرج المتوقع هو "i am a student". هذا يعني أننا نرغب أن يقوم النموذج باخراج توزيعات احتمالية متتالية بحيث:
يتم تمثيل كل توزيع احتمالي بواسطة متجه عرضه vocab_size يساوي ٦ كما هو الحال في المثال الذي استعرضنا آنفاً (في الواقع يمكن أن يكون أكبر من ذلك بكثير، مثلا مساوي ل 30,000 أو 50,000)
توزيع الاحتمال الأول له أعلى احتمال في الخلية المرتبطة بكلمة "i"
توزيع الاحتمال الثاني له أعلى احتمال في الخلية المرتبطة بكلمة "am"
وهكذا دواليك حتى يشير توزيع الإخراج الخامس إلى رمز "< eos نهاية الجملة>" ، والذي يحتوي أيضًا على خلية مرتبطة به من أصل 10,000 مفردة من مفردات المعجم.

توضح الصورة السابقة التوزيعات الاحتمالية المستهدفة التي سنقوم بتدريب نموذجنا عليها في مثال التدريب لجملة عينة واحدة.
بعد تدريب النموذج لوقت كافٍ على مجموعة بيانات كبيرة بما يكفي ، نأمل أن تبدو التوزيعات الاحتمالية الناتجة كما هو موضح في الصورة التالية:

في الحقيقة نحن نأمل عند التدريب أن ينتج النموذج الترجمة الصحيحة التي نتوقعها للجملة المدخلة. بالطبع لا يوجد مؤشر حقيقي إذا كانت هذه العبارة جزءًا من مجموعة بيانات التدريب (يمكنك أن تطلع على مفهوم التحقق المتقاطع cross validation). يمكننا ملاحظة أن كل موقع يحصل على قيمة احتمال وإن كانت ضئيلة جداً وليس من المحتمل أن تكون الكلمة المقابلة للموقع مخرجاً صحيحاً في تلك الخطوة. هذه خاصية مفيدة جدًا لـ سوفت ماكس softmax والتي تساعد في عملية التدريب.
نظرًا لأن النموذج ينتج المخرجات بشكل متسلسل واحداً تلو الأخر، يمكننا أن نفترض أن النموذج يختار الكلمة ذات الاحتمال الأعلى من توزيع الاحتمالات هذا ويتخلص من الباقي. تسمى هذه الطريقة بفك التشفير الجشع greedy decoding.
هناك طريقة أخرى للقيام بنفس المهمة وهي طريقة التمسك hold. على سبيل المثال، لنفترض أنه في خطوة ما كانت أعلى قيم الاحتمال هي التي حصلت عليها كلمتي "I" و "a"). في الخطوة التالية، يمكن إكمال العملية عبر طريقين مختلفين: الأول بافتراض أن موقع المخرج الأول كان كلمة "I" ، ومرة أخرى بافتراض أن موقع المخرج الأول كان الكلمة "a" ، وبالتالي يتم الاحتفاظ بنسخة النموذج الذي ينتج عنه خطأ أقل بالنظر إلى الموقعين # 1 و # 2. نكرر هذا للموضعين # 2 و # 3، وهكذا دواليك.
تسمى هذه الطريقة "البحث عن الشعاع beam search". في مثالنا، كان حجم الشعاع beam_size يساوي اثنين، بمعنى أنه في جميع الأوقات ، يتم الاحتفاظ بفرضيتين جزئيتين أو ترجمات غير مكتملة unfinished translations في الذاكرة. والأعمدة العلوية top_beams تساوي أيضًا اثنان، بمعنى أننا سنقوم بإرجاع ترجمتين كمخرج من النموذج. Beam_size و top_beams عبارة عن معاملات hyperparameters يمكنك تجربتها وتغيررها أثناء التدريب.